 하나씩 점을 찍어 나가며
하나씩 점을 찍어 나가며가장 먼저, 아래 글을 참고했다.
Stop using df.iterrows()
This morning I came across an article with tips for using Pandas better. One of the claims was that df.itertuples() should be used instead…
medium.com
Pandas dataframe 에서 이터레이션 도는거 꽤 중요하다.
경험상, 보통 df.iterrows() 돌리는데, 이거 엄청느리다.
아무튼 글의 핵심은 이거다.
dataframe 에서 행 단위 반복문 쓸 때, df.iterrows() 쓰지말고 df.itertuples() 쓰세요.
차이가 무지막지하게 큽니다.
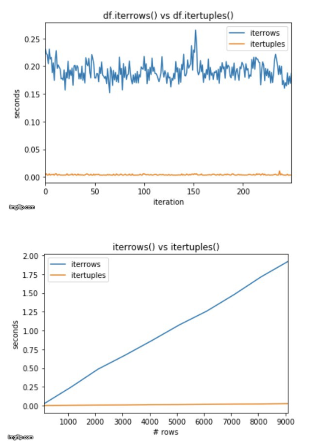
이터레이션 도는데 뭐가 이렇게 차이나지? 싶었는데,
저자는 다음과 같은 말을 던진다.
df.iterrows() yields a Pandas Series, and df.itertuples() yields a named tuple.
The API is still the same to access elements in the object yielded at each iteration.
Series 가 아닌 named tuple 을 반환해서, 더 빠르다고 하는데,
아무래도 Series 오브젝트가 더 용량이 비대하니까, 메모리에 올라가는 I/O 가 더 느린듯 하다.
참고로 쓰는 방법은 다음과 같다.
df = pd.DataFrame([[1,2,3], [4,5,6]], columns=['A', 'B'])
for row in df.itertuples():
# 각 열에 대한 정보는 getattr 로 얻어와야 한다.
col_A = getattr(row, 'A')
col_B = getattr(row, 'B')
print(col_A, col_B)
# output
# 1 4
# 2 5
# 3 6보는 김에, Pandas DataFrame 이나 Series 를 반복문 돌 때, 어떤 방법이 성능 최적화 되어있는지도 확인해봤다.
아래 링크를 참고했다.
A Beginner’s Guide to Optimizing Pandas Code for Speed
If you’ve done any data analysis in Python, you’ve probably run across Pandas, a fantastic analytics library written by Wes McKinney. By…
engineering.upside.com
결론적으로 말하면, 각 방법별 이터레이션 성능은 다음과 같다.

위에서 아래로 올수록 성능이 좋은 방법들이다.
다음에 시간남으면 직접 돌려서 비교해봐야지.
'더 나은 엔지니어가 되기 위해 > 파이썬을 파이썬스럽게' 카테고리의 다른 글
| 파이썬 클린 코드 2 - 클린 코드와 코딩 가이드라인 (2) | 2020.05.09 |
|---|---|
| 파이썬 클린 코드 1 - 파이썬스러운 코딩을 파이썬 문법 컨셉 (0) | 2020.05.03 |
| python 멀티 프로세싱은 parmap 으로 하자. (15) | 2019.07.22 |
| pandas, 데이터 프레임 합치는 방법 중 뭐가 제일 빠를까 (0) | 2019.05.23 |
| 파이썬 제너레이터 간단 정리 (0) | 2019.04.29 |

