 하나씩 점을 찍어 나가며
하나씩 점을 찍어 나가며다음 3가지가 가장 핵심 기초라고 생각되어 정리해본다.
- 기본 개념과 용어
- 트랜잭션
- 테이블 설계와 정규화
1. 기본 개념 단어
1.1. 용어
- 관계형 데이터 모델
- 릴레이션, 속성(필드, 컬럼), 튜플(레코드, 행)
- 도메인
- 각 필드가 가질 수 있는 모든 값들의 집합
- 원자값(atomic value, 더 이상 분리되지 않는 값)이어야 함
- 스키마
- 테이블 정의에 따라 만들어진 데이터 구조
- 차수
- 테이블 스키마에 정의된 필드의 수
- 테이블 인스턴스
- 테이블 스키마에 현실 세계의 데이터를 레코드로 저장한 형태
- 기수(cardinality)
- 테이블 인스턴스의 레코드의 수
2. 트랜잭션
2.1. 정의
데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위
'하나의 작업' 에는 하나의 목표를 위해 여러 테스크가 포함된다.
예를 들어, 다음과 같이 연속해서 테스크를 진행한다고 하자.
# 하나의 트랜잭션은 다음으로 이루어져있다.
1. 검색 후,
2. 조건에 따라 뽑아낸 뒤,
3. 다시 삽입한다.이 3가지의 수행을 하나의 '작업' 으로 정의하고 싶을 때, 이 작업을 곧 트랜잭션이라고 부른다.
2.2. 특징
흔히, ACID 라고 외운다.
- 원자성(Atmoicity)
- 트랜잭션이 하나의 단위로 수행돼야 한다.
즉, 트랜잭션 내 테스크가 모두 수행되거나, 아니면 아예 모두 수행되지 않아야 한다. - 수행 중, 중간에 오류가 날 경우 수행완료 된 것도 모두 수행되지 않은 것으로 처리해야함을 의미한다.
- 트랜잭션이 하나의 단위로 수행돼야 한다.
- 일관성(Consistency)
- 트랜잭션 처리 결과가 항상 일관성이 있어야 한다.
- 트랜잭션이 진행되는 동안, 데이터베이스가 변경되더라도, 처음에 트랜잭션을 진행하기 위해 참조한 데이터베이스로 진행된다.
- 독립성(Isolation)
- 서로 다른 트랜잭션이 동시에 수행될 때, 다른 트랜잭션의 연산에 끼어들 수 없다.
- 또한 하나의 트랜잭션이 완료될 때 까지, 이 트랜잭션의 결과를 참조할 수 없다.
- 즉, 트랜잭션 끼리는 독립적으로 수행되어야 함을 의미한다.
- 지속성(Durability)
- 트랜잭션이 성공적으로 완료되었을 경우, 결과는 영구적으로 반영되어야 한다.
2.3. Commit & Rollback
원자성(Atomic) 과 관련된 개념이다.
- Commit
- 하나의 트랜잭션이 성공적으로 끝났고, DB가 다시 일관된 상태에 있을 때, 하나의 작업이 완료 된 것을 시스템에 알리는 연산이다.
- Rollback
- 트랜잭션 처리 중, 오류가 생겼을 때 트랜잭션의 원자성을 구현하기 위해, 트랜잭션 내 수행 완료한 테스크들을 모두 취소하는 연산이다.
2.4. 격리 수준
독립성(Isolation) 과 관련된 이슈다.
격리성 관련 문제 현상
- Dirty Read
- 다른 트랜잭션에 의해 수정됐지만 아직 커밋되지 않은 데이터를 읽는 것을 말한다.
- 변경 후 아직 커밋되지 않은 값을 읽었는데 변경을 가한 트랜잭션이 최종적으로 롤백된다면 그 값을 읽은 트랜잭션은 비일관된 상태에 놓이게 된다.
- ex.
SELECT(T1)->UPDATE(T2)(commit) ->T1문제 발생!
- Non-Repeatable Read
- 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데,
그 사이에 다른 트랜잭션이 값을 수정 또는 삭제하는 바람에 두 개의 같은 쿼리 결과가 다르게 나타나는 현상 - ex.
SELECT(T1)->UPDATE(T2)(commit) ->SELECT(T1)->T1문제 발생!
- 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데,
- Phantom Read
- 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 없던 유령(Phantom) 레코드가 두 번째 쿼리에서 나타나는 현상
- ex.
SELECT(T1)->INSERT(T2)(commit) ->SELECT(T1)->T1문제 발생!
격리성 수준
아래로 내려갈수록 트랜잭션간 고립 정도가 높아지며, 성능이 떨어지는 것이 일반적이다.
- Read Uncommitted
- Read Commited
- Repeatable Read
- Serializable Read

대부분 DBMS가 Read Committed를 기본 트랜잭션 격리성 수준으로 채택하고 있으므로 Dirty Read가 발생할까 걱정하지 않아도 되지만, Non-Repeatable Read, Phantom Read 현상에 대해선 세심한 주의가 필요하다.
3. 테이블 설계
테이블을 어떤 기준으로 나눠서 데이터를 관리하게 만들지 기준이 되는 개념이다.
이 때, 정규형이라는 단계를 나눠, 각 단계 수준에 맞게 테이블을 설계한다.
3.1. 정규화가 필요한 이유
테이블을 잘 만들지 않으면 (정규화를 하지 않으면) 어떤 문제가 발생하는지 아래 링크를 보면 나와있다.
데이터베이스 정규화 - 이상현상 & 함수적 종속성
개요 삽입이상 (Insertion Anomaly), 갱신이상 (Update Anomaly), 삭제이상 (Deletion Anomaly) 설명 함수적 종속성 (Functional Dependency) 에 대해 알아본다.
yaboong.github.io
- 삽입이상
- 새 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제
- 갱신이상
- 중복 튜플 중 일부만 변경하여 데이터가 불일치하게 되는 모순의 문제
- 삭제이상
- 튜플을 삭제하면 꼭 필요한 데이터까지 함께 삭제되는 데이터 손실의 문제
3.2. 함수적 종속성
정규화를 하는 과정에서, 필드간의 릴레이션을 관심있게 보는데, 여기에 도입된 개념이 '함수적 종속성'이다
X, Y 가 각각 테이블의 필드를 나타낼 때,
X -> Y 는 Y는 X에 종속되었음을 의미한다.
- 부분 함수적 종속
- 속성집합 Y 가 속성집합 X 의 전체가 아닌 일부분에도 함수적으로 종속됨을 의미한다.
- 완전 함수적 종속
- 속성집합 Y 가 속성집합 X 전체에 대해서만 함수적으로 종속된 경우를 말한다.
예시.
학번 -> 이름
{학번, 과목코드} -> 성적 # 완전 함수적 종속.
{학번, 과목코드} -> 이름 # 부분 함수적 종속, 왜냐하면 X일부인 '학번' 으로도 종속이므로.일반적으로 함수적 종속성을 말하면 완전함수종속을 의미한다.
3.3. 정규화 단계와 과정
각 수준에 맞게 테이블을 만들어가는 과정을 보자.
다음 링크를 참고, 번역했다.
What is Normalization? 1NF, 2NF, 3NF & BCNF with Examples
1. What is DBMS? A Database Management System (DBMS) is a program that controls creation,...
www.guru99.com
각 단계는 그 이전 단계의 기준들을 포함한다.
초기 테이블의 모습은 다음과 같다.
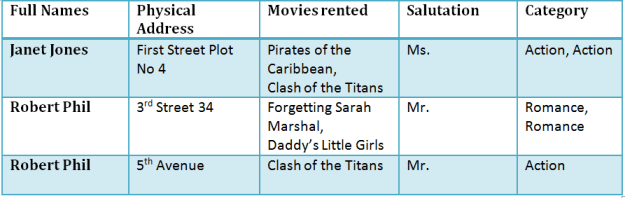
제 1정규형 (1NF)
각 테이블 셀에는 단일 값이 포함되어야한다.
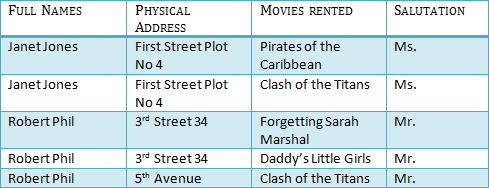
제 2정규형 (2NF)
종속성을 띄고 있는 데이터를 분리한다.
즉, 기본키를 제외한 나머지 필드들은 기본키에만 종속되어야 한다


제 3정규형 (3NF)
테이블 안에 두 번 이상 연결 된 종속을 가지지 않는다.
다른 말로, 이행 종속을 가지지 않는다라고 하는데, 이행 종속은 다음과 같은 것이다.
X -> Y
Y -> Z위와 같은 경우 결론적으로 X -> Z 의 종속이 성립되는데, 이렇게 꼬리에 꼬리를 물어 생기는 종속을 이행 종속이라고 한다.
이를 X -> Y 테이블, Y -> Z 테이블로 분리시키는 것이 제 3정규형이다.

위 테이블을 보면
Membership ID -> Full names
Full names -> Salutation임을 알 수 있다. 즉, 결과적으로 Membership ID -> Salutation 이라는 결과가 나오는데, 이를 다음과 같이 나눠주어야 한다.
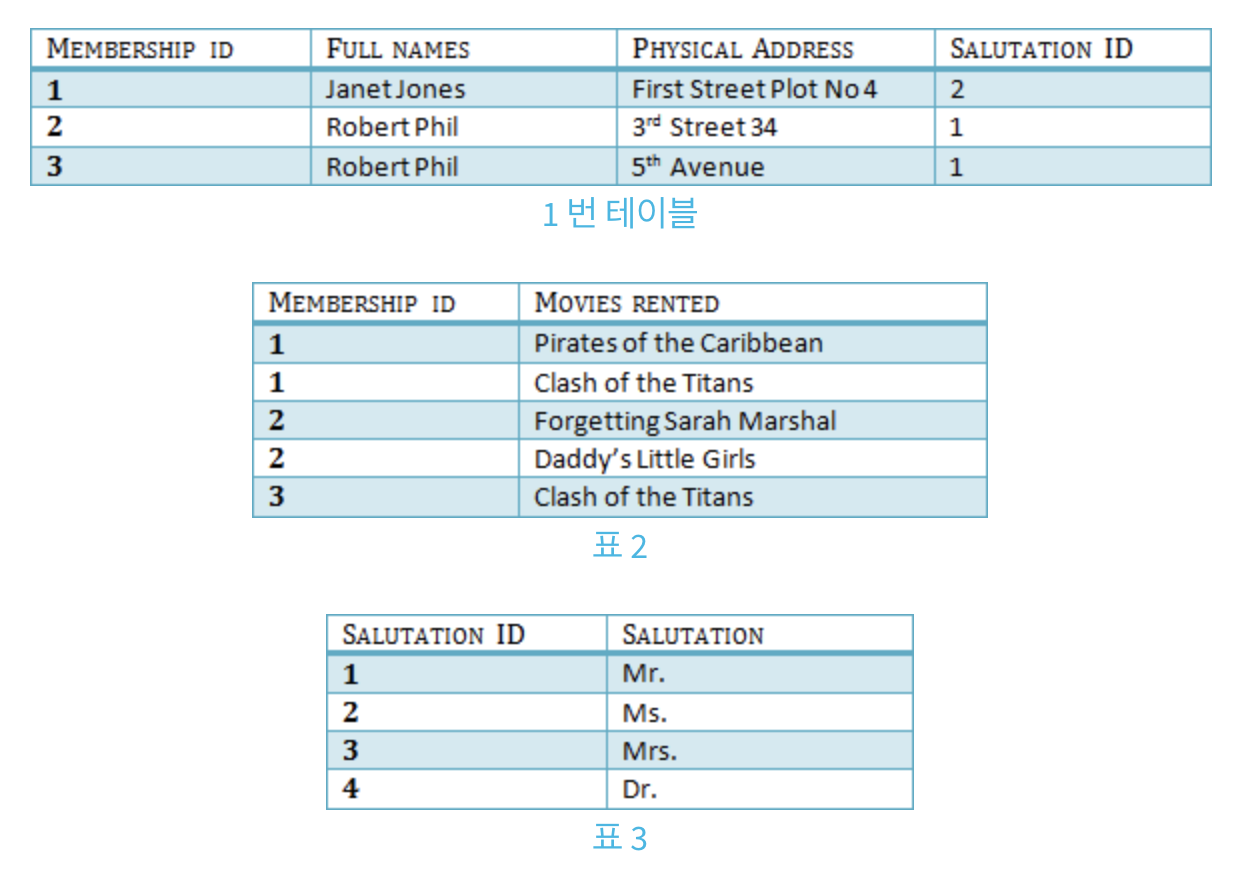
정규형은 제1정규형부터 제5정규형까지 있다.
하지만 제3정규형까지 적용하더라도 어느정도 괜찮다고 한다.
'취업과 기본기 튼튼 > 빽 투더 기본기' 카테고리의 다른 글
| 빽 투더 기본기 [OS 2편]. 쓰레드 (0) | 2019.09.27 |
|---|---|
| 빽 투더 기본기 [OS 1편]. 프로세스 (0) | 2019.09.27 |
| 빽 투더 기본기 [알고&자구 7편]. 프림 알고리즘 (0) | 2019.04.22 |
| 빽 투더 기본기 [알고&자구 6편]. 크루스칼 알고리즘 (0) | 2019.04.20 |
| 빽 투더 기본기 [알고&자구 5편]. 다익스트라 알고리즘 (3) | 2019.04.19 |



