 하나씩 점을 찍어 나가며
하나씩 점을 찍어 나가며1. 대회 개요
한 마디로 말해, 기존의 Sales 데이터를 가지고, 미래의 Sales 량을 예측하는 대회입니다.
정확히는, 2013년 1월~2015년 10월의 모든 shop 내 item들의 하루 단위의 세일즈량이 주어지고,
이후 다음 달(2015년 11월)의 각 shop의 각각의 item 세일즈량의 총 합을 예측해야 합니다.
"How to win a data science competition" Coursera course 의 마지막 프로젝트라고도 하는군요.
2. 데이터
데이터들은 다음과 같이 제공됩니다.
sales_train.csv - the training set. Daily historical data from January 2013 to October 2015.
test.csv - the test set. You need to forecast the sales for these shops and products for November 2015.
sample_submission.csv - a sample submission file in the correct format.
items.csv - supplemental information about the items/products.
item_categories.csv - supplemental information about the items categories.
shops.csv - supplemental information about the shops.조금 더 구체적으로 살펴보면, 다음과 같습니다.
1) sales_train.csv

- date : 말 그대로 날짜입니다. 하루 단위로 되어있습니다.
- date_block_num : 월을 0부터 연속된 수로 변환한 수입니다. 예를들어, 13년 1월을 0으로 두고, 13년 12월은 11로, 그리고 14년 1월은 12로.. 이런식입니다.
- shop_id : 말 그대로 shop의 id 입니다.
- item_id : 말 그대로 item의 id 입니다.
- item_price : 해당 날짜의 item_id 에 해당하는 item의 가격입니다.
- item_cnt_day : 해당 날짜에 item_id 에 해당하는 item이 팔린 갯수입니다. 우리가 예측해야하는 변수이기도 합니다.
2) test.csv
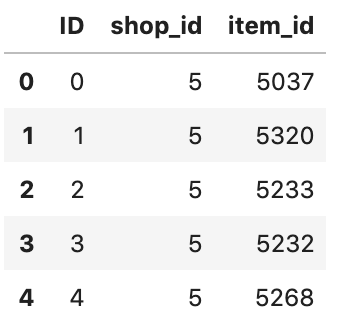
2015년의 11월의 각 shop 내 item들의 item_cnt_day 을 예측해야 한다고 했습니다. 이에 대한 기본 틀을 제공해주는 파일입니다.
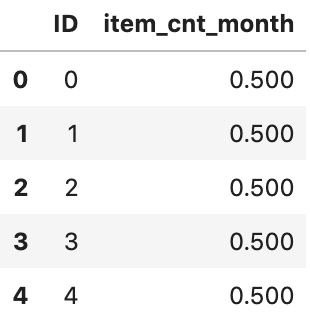
위 데이터로 테스트한 뒤, 최종적으로 아래와 같은 꼴로 바꾸어 제출해야 합니다.
3) items.csv

- item_name : 말 그대로 item 이름입니다. 저도 처음보는 문자네요.
- item_category_id : 말 그대로 item 이 속해있는 카테고리 id 입니다.
4) item_categories.csv
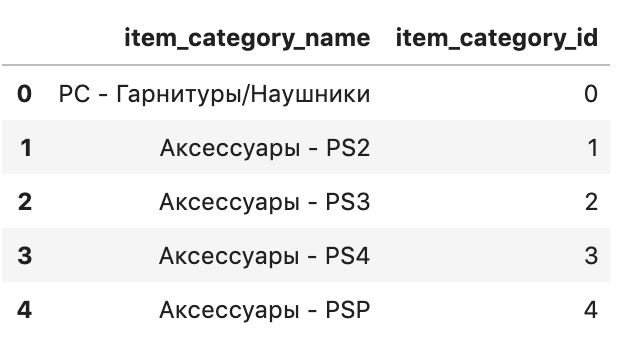
item_category_id의 이름을 담고있는 파일입니다.
0번을 행을보니, id 0 번은 PC 와 관련된 카테고리인 것 같군요.
5) shops.csv

shop_id의 이름을 담고있는 파일입니다.
3. 모델 평가
이 대회에서 모델 평가는 RMSE(root mean squared error)를 사용합니다.
이 후 포스팅 부터는, 이 대회에서 보팅이 높았던 커널 중, 쉬운 것 부터 하나씩 보겠습니다.
'데이터와 함께 탱고를 > 커널 공부하기' 카테고리의 다른 글
| [Predict Future Sales] xgboost 커널 리뷰 (4) | 2019.08.01 |
|---|---|
| [Predict Future Sales] playground 커널 리뷰 2 (0) | 2019.07.29 |
| [Predict Future Sales] playground 커널 리뷰 1 (2) | 2019.07.28 |
| [Predict Future Sales] playground 커널 리뷰 0 (0) | 2019.07.28 |
| 커널을 공부해본다. (0) | 2019.07.25 |


