 하나씩 점을 찍어 나가며
하나씩 점을 찍어 나가며0. 들어가기 전, 알아야 할 상식
운영체제의 선수과목인 시스템 프로그래밍 내용 중, 운영체제와 매우 밀접하게 연관된 내용이 있는데, 이 부분을 먼저 알아야 한다. 바로 컴파일러, 어셈블러, 링커, 로더에 대한 기본 이해다.
먼저 이 개념을 명확히 하고가자.
내용은 https://seohs.tistory.com/259 을 참고했다.
먼저, 하나의 코드가 프로그램이 되고, 프로그램이 프로세스가 되는 과정은 다음과 같다.
코드 작성 -- (컴파일) --> 오브젝트 파일 -- (링킹) --> 실행 파일(=프로그램) -- (로드) --> 메모리 적재 및 수행(=프로세스)
컴파일러
사용자가 작성한 원시코드를 컴퓨터가 읽을 수 있는 형태의 오브젝트 파일로 만드는 프로그램
어셈블러
어셈블리어 코드를 기계어 코드로 변환시켜주는 프로그램.
명확히 말하면, 어셈블러는 큰 의미 컴파일러 내부에 속한다.
큰 의미의 컴파일러는 사실 다음과 같이 구성된다.
(원시 코드) -> (컴파일러) -> (어셈블리어 코드) -> (어셈블러) -> (기계어 코드 = 오브젝트 코드)
링커
프로그램이 되기 위해 여러 개의 오브젝트 파일과 라이브러리를 엮는 과정(링킹)을 수행하는 프로그램
로더
사용자가 프로그램을 실행하면, 메모리에 적재하는 일(로드)을 수행하는 프로그램
1. 기본 개념
1.1. 주소 바인딩
코드에서 변수로 쓰이던 공간들이 실제 메모리에 매핑되는 동작을 '바인딩' 이라고 한다.
주소를 바인딩하는 시간은 다음과 같이 나뉜다.
- 컴파일 타임
- 로드 타임
- 실행 타임
1.2. Logical vs Physical Address
Logical Address (= Virtual Address)
CPU에 의해 생성되는 주소다. 즉 실제적인 물리주소와는 관련없고, 메모리에 적재되기 전 가지는 가상주소다.
Physical Address
실제 메모리(RAM) 상에서의 주소다.
MMU (Memory Management Unit)
Logical Address 를 Physical Address 로 매핑시켜주는 하드웨어 장치다.
예를 들어, base register 가 14000 이고, logical address 가 346이면, 실제 Physical Address 는 14346이 된다.
1.3. Static vs Dynamic Linking

Static Linking
컴파일 타임에, 라이브러리 파일 전체가 오브젝트 파일에 복사된다.
실행 파일의 크기가 비대해질 수 있다.
또한 실행 시, 모든 코드가 로드된다.
Dynamic Linking
런타임 중에 호출된 라이브러리 파일이 최초 한 번만, 메모리 공간에 적재된다.
필요한 코드만 로드된다.
또한 라이브러리 갱신에 용이하다.
2. Swapping
프로세스 실행 도중, 일시적으로 주기억장치에서 보조기억장치로 옮겨진 후, 나중에 다시 주기억장치에 로드할 수 있게한다. 이 과정을 스와핑이라 한다.
우선순위에 의해 발생되면 roll in, roll out 이라는 용어를 사용한다.

3. 메모리 할당
3.1. 연속적 할당
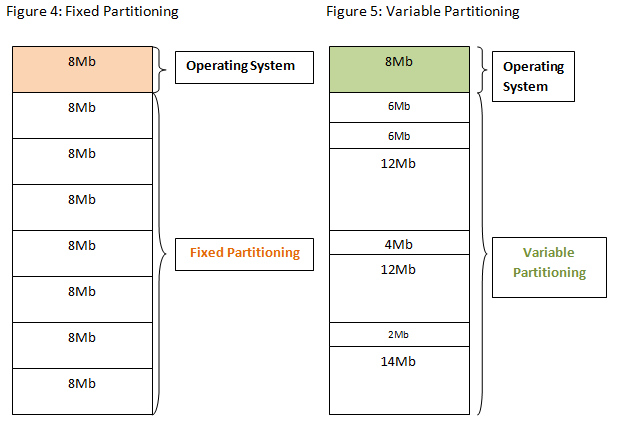
Fixed size
메모리를 고정된 크기로 일정하게 나누어(파티션), 각각의 프로세스에게 할당한다.
즉, 파티션의 개수가 곧 가능한 멀티 프로세스의 수(degree of multiprogramming) 와 같다.
관리는 용이하나, 적절한 파티션의 크기를 잡기가 어렵고, 메모리 낭비도 심하다.
지금은 안쓴다.
Variable size
Hole = 할당 가능한 메모리 블락
OS 는 할당한 파티션들과, 할당 가능한 파티션(hole) 둘 다 관리해야 한다.
Fixed Size 보다 훨씬 유연하지만, 이제 이슈는 여러 hole 들이 있을 때 프로세스를 어떻게 어디에 할당할 것인지에 대한 것이다.
이에 다음과 같은 방법들이 있다.
- First-fit
- 현재 hole 리스트 탐색 중, 프로세스가 들어갈 수 있는 첫 번째 hole 을 할당한다.
- Best-fit
- 현재 hole 리스트 탐색 중 프로세스의 들어갈 수 있는 가장 작은 hole을 할당한다.
- Worst-fit
- 현재 hole 리스트 중 그냥 제일 큰 hole 을 할당해준다.
그러나 Variable Size 방법은 여전히 최적화 문제가 있는데,
모든 프로세스들이 할당되지 않은 파티션들(holes)을 '최대한' 활용하지 못하는 문제가 생긴다.
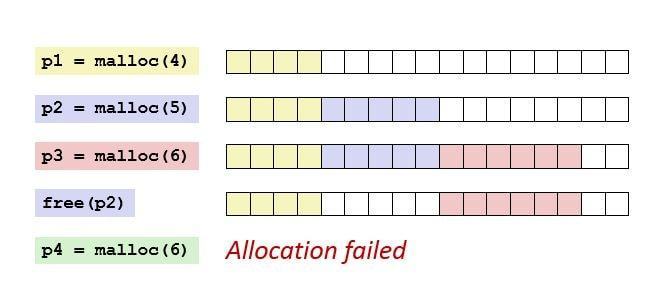
즉, 위와 같이 메모리에 충분히 여유공간이 있는데, 모두 조각나(fragmentation) 있어, 메모리 공간을 제대로 활용하지 못하는 상황이 발생한다.
- Internal Fragmentation
- OS는 프로세스가 요청한 메모리 공간보다 조금 더 많이 할당해주는데, 이 메모리 공간이 활용되지 않는다면, 이는 낭비다.
- External Fragmentation
- 위 그림과 같은 상황으로, 활용가능한 메모리 공간이 연속적이지 않아서 사용할 수 없는 경우다.
보통 할당된 영역이 N개 이면, 0.5N 개의 영역이 fragmentation 으로 낭비된다.
이에 대한 해결책으로 compaction 이 있다.

이는, 현재 프로세스들의 메모리 공간을 재배치하여, fragmented 한 hole 들을 continuous 하게 만드는 방법이다. 하지만, 전체 프로세스들을 재배치한다는 점에서 오버헤드가 있다.
3.2. 비연속적 할당
Paging
Fragmentation 문제를 해결하기 위해서, 일정 크기의 단위로 나누어서 분산 적재하는 방법이다.
다음과 같은 방법을 사용한다.
- 물리적 기억장치를 고정된 크기로 나눈다. 이를 프레임이라 한다. (보통 4KB)
- 논리적 주소공간도 프레임과 같은 크기로 나눈다. 이를 페이지라 한다.
- 논리주소는 페이지 번호(number)와 오프셋(offset) 으로 구성한다.
- 별도의 페이지 테이블이 존재하여, 논리주소의 페이지 번호로 이 테이블에 접근한다.
- 페이지 테이블에는 각 페이지 번호에 매핑되는 물리주소 정보를 담고있다.
- 즉 실제주소는 페이지 테이블에 매핑되는 물리주소 + 오프셋으로 만들어진다.좀 더 구체적으로 보면, 다음과 같다.

예를들어, 32비트 명령체계를 가진 CPU를 사용한다고 해보자.

- 페이지와 프레임의 크기가 4KB 라면, 한 프레임 내 1Byte 메모리블럭이 2^12 개 있는 것이다.
(근데 사실 하나의 32비트에서 하나의 명령어는 4Bytes 로 구성되어있으므로, 접근은 4Bytes 단위로 한다.
즉 접근은 4Bytes 단위지만, 주소는 1Byte 로 단위로 매핑되어 있음.) - 그렇다면, 한 프레임 내에 2^12 개의 주소를 가질 수 있다는 뜻이고,
32비트 명령어안에 뒤에 12비트는 오프셋을 담는 위치가 된다. - 그러면 나머지 20비트는 페이지 넘버의 영역이다.
즉 우리는 2^20개의 페이지 주소(공간) 을 갖는다!
정리하면, 다음과 같다.
논리 주소 공간의 크기가 2^m 이고,
페이지의 크기가 2^n 일 때,
=> 주소의 하위 n 비트는 오프셋, 상위 m-n 비트는 페이지 번호가 된다.

페이징을 사용하면, 외부 단편화는 일어나지 않지만 내부 단편화(Fragmentation)는 일어날 수 있다.
일반적으로, 프로세스마다 프레임의 절반크기 정도의 내부 단편화가 일어난다.
Page Table
페이지 테이블은 메인 메모리에 상주한다. 즉, 논리주소는 메모리 내 페이지 테이블을 거쳐, 원래 목적 메모리 주소에 도달하게 되는, 즉 2번 메모리를 접근하여 명령어를 수행하게 된다.
메인 메모리의 모든 페이지 엔트리를 갖고있기 때문에, 사이즈가 메인 메모리에 비례하여 커진다.
한편, 논리주소에서 페이지 넘버는 페이지 테이블에서의 인덱스이기 때문에, 검색 비용이 들지 않는다.
페이지 테이블에는 모든 프레임에 대한 테이블을 기준으로 나누고 다음의 내용을 담는다.
- 각 프레임의 할당 여부
- 할당 되어있을 경우, 어떤 프로세스가 할당되어있는지
- 물리 메모리의 시작 주소
또, 각 프로세스마다 PCB 에 페이지 테이블을 가진다.
프로세스마다 독립적인 가상 공간이 주어지고, 필요한 물리적 메모리 공간과 매핑할 수 있어야하기 때문이다.
즉, 전역 메모리에 상주해있는 페이지 테이블은, 프로세스 단위로 메모리를 매핑하는 것이고,
각 프로세스 내 페이지 테이블은, 지역변수 등 코드 단위로 메모리를 매핑하는 것이다.
실질적으로 할당가능한 프레임 엔트리는 프레임 테이블이라는 애가 별도로 관리한다.
한편, PCB 내 페이지 테이블이 들어가므로, Context Switching 시 overhead 가 더 늘어난다..
페이징 시스템에서는 MMU 가 곧 페이지 테이블이 된다.
또한, 이런 페이징 시스템은 OS 가 하는 것이 아닌, 별도의 하드웨어에서 한다.
Paging 특징 정리
- 사용자/프로세스의 편의성
- 연속된 논리 주소 공간을 독립적으로 사용
- MMU 에 의한 비교적 빠른 주소 변환
- 프레임 단위의 비연속적 메모리 할당
- 외부 단편화가 없음.
- 하지만 내부 단편화는 있음 (필수불가결).
- CS 시 오버헤드 증가
- 공유 페이지를 통한 IPC 효율성 증가
참고
- 이선우님 블로그
- OS 에 대한 전반적인 쉬운 강의를 텍스트로 세세하게 듣고싶다면 꼭 읽어보길.
'취업과 기본기 튼튼 > 빽 투더 기본기' 카테고리의 다른 글
| 빽 투더 기본기 [OS 8편]. 가상 메모리 관리 (0) | 2019.10.27 |
|---|---|
| 빽 투더 기본기 [OS 7편]. 메모리 관리 2 (0) | 2019.10.25 |
| 빽 투더 기본기 [OS 5편]. 뮤텍스와 세마포어 (0) | 2019.09.28 |
| 빽 투더 기본기 [OS 4편]. 동기화와 Peterson' 알고리즘 (3) | 2019.09.28 |
| 빽 투더 기본기 [OS 3편]. CPU 스케쥴링 (0) | 2019.09.28 |


