 하나씩 점을 찍어 나가며
하나씩 점을 찍어 나가며1. Model Ensemble
Model ensemble 은, 말 그대로 모델들의 앙상블. 즉 여러 모델들을 함께 사용하여 기존보다 성능을 더 올리는 방법을 말한다.
이게 ML(Machine Learing) 모델이면 ML Model Ensemble 이 된다.

2. Ensemble 종류
그럼 구체적으로 어떤 식으로 모델들을 Ensemble 하는지 살펴보자.
2.1. Bagging
Bagging은 입력 데이터를 모델 수 만큼 나눈 뒤, 각각 학습시킨다.
이후, Test dataset 을 각 모델에 넣어 예측할 때, 출력되어 나온 예측 값들을 voting 하여, 보다 더 투표를 받은 예측 값이 최종 예측값이 된다.
뭔가 민주주의 공화국 느낌이다.

Bagging 의 가장 대표적인 모델이 바로 Random Forest 이다.
Random Forest는 단일 모델인 Decision Tree 들을 여러개 두어, 각각 훈련시킨 뒤, 최종적 예측 결과를 Voting 하여 하나의 값을 뽑아내는데, Bagging 방식을 그대로 따라가고 있다.
2.2. Boosting
Boosting 은 Bagging 보다 살짝 더 복잡한데, 아래 그림을 보며 설명해보겠다.
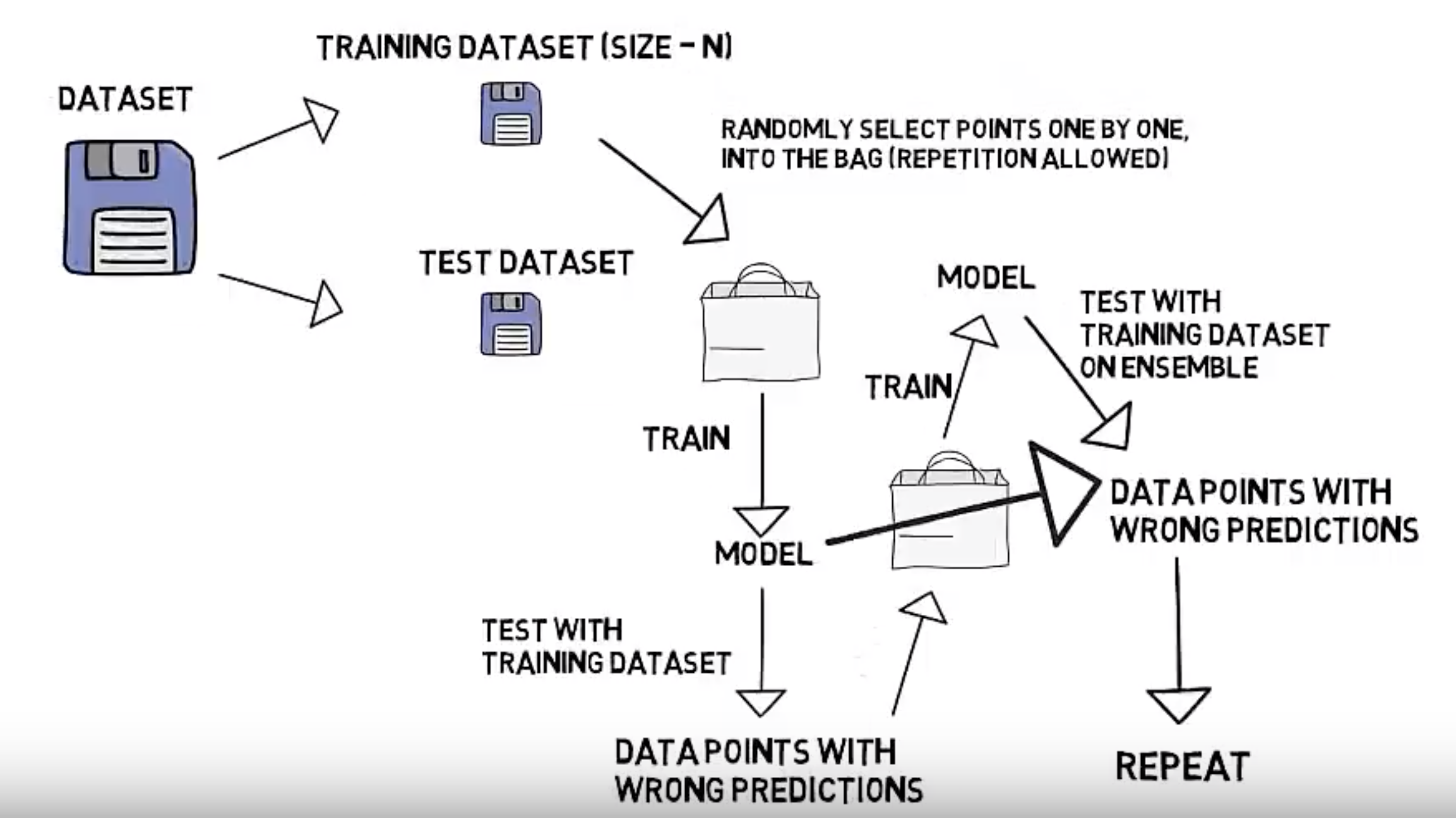
- 먼저, Train dataset 과 Test dataset 을 나눈다.
- 이제, Train dataset 을 가지고 dataset을 하나 또 만든다. 그리고 이 dataset 으로 model 을 학습시킨다.
- 학습시킨 모델에 이제, Train dataset 전체를 가지고 validation 을 한다.
- 이제 다시 Train dataset 를 가지고 새로운 dataset 을 만들건데, 이 때, 3에서 잘못 예측한 데이터들이 이 새로운 dataset 에 포함되게 dataset 을 만든다. (정확히는 오류 데이터에 가중치를 부여하여 샘플링될 때 더 잘 뽑히게 한다.) 이게 핵심이다.
- 이렇게 만든 dataset 을 가지고, 다시 새로운 모델을 만들어 학습한다.
- 그리고 다시 Train dataset 전체를 가지고 validation 을 하는데, 이 때, 3에서 만든 모델도 같이 사용한다.
즉 예측 값은 모델이 2개이므로, 2개의 세트로 나올 것이고, 이를 voting 을 통해, 하나의 예측 값을 사용한다. - 그럼 다시 또, 잘못 예측된 데이터가 있을텐데, 4에서 한 것 처럼, 이 데이터를 포함하는 dataset 을 만든 후, 이를 반복한다.
boosting 의 핵심은, 하나의 모델을 점점 수를 추가해가며 앙상블 시키는데,
추가되는 모델들이 이전에 잘못 예측되었던 데이터에 좀 더 fitting 되게 만든다는 것이다.
에러를 줄이기 위해, 좀 더 집중하는 양상이랄까? 그래서 이름도 boosting 인가 보다.
아 그리고, 이런 Boosting 기법은 더 있는데, 여기서 설명한게 가장 기초적인 Boosting 기법으로,
정확히는 Ada Boosting 이라고 한다.
참고 및 출처
Udacity - Boosting 유튜브 영상
The semicolon - Ensemble Learning, Bootstrap Aggregating (Bagging) and Boosting 유튜브 영상
'데이터와 함께 탱고를 > 머신러닝' 카테고리의 다른 글
| Categorical Value Encoding 과 Mean Encoding (3) | 2019.09.07 |
|---|---|
| Gradient Boost (3) | 2019.08.09 |
| AdaBoost (5) | 2019.08.07 |
| Random Forest (2) | 2019.08.07 |
| Decision Tree (1) | 2019.08.05 |



