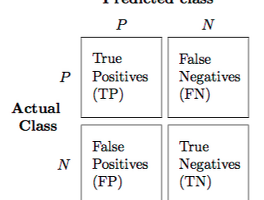
 분류 모델에 대한 성능 평가 지표들
Precision & Recall Precision 은 모델의 예측 값 중, 실제 값과 같은 데이터의 비율을 말하고, Recall 은 실제 값 중, 모델의 예측 값과 같은 데이터의 비율을 말한다. 다시 정리하면, 예측해야할 값의 클래스가 A, B, C 가 있다고 할 때, Precision = (예측 데이터 중, 실제 클래스 A 인 데이터의 수) / (클래스 A 로 예측된 값들의 데이터 수) Recall = (실제 데이터 중, 클래스 A 로 예측된 값들의 데이터 수) / (실제 클래스 A 인 데이터의 수) 일반적으로 각 클래스 A, B, C 에 대한 각각의 성능 지표를 구한 뒤, 평균을 내어 하나의 지표로 통합하여 표현한다. 평균 외에 다른 방법도 있긴 하다. 이 두 값 모두 0~1 사이의 값을 가지며 1..
분류 모델에 대한 성능 평가 지표들
Precision & Recall Precision 은 모델의 예측 값 중, 실제 값과 같은 데이터의 비율을 말하고, Recall 은 실제 값 중, 모델의 예측 값과 같은 데이터의 비율을 말한다. 다시 정리하면, 예측해야할 값의 클래스가 A, B, C 가 있다고 할 때, Precision = (예측 데이터 중, 실제 클래스 A 인 데이터의 수) / (클래스 A 로 예측된 값들의 데이터 수) Recall = (실제 데이터 중, 클래스 A 로 예측된 값들의 데이터 수) / (실제 클래스 A 인 데이터의 수) 일반적으로 각 클래스 A, B, C 에 대한 각각의 성능 지표를 구한 뒤, 평균을 내어 하나의 지표로 통합하여 표현한다. 평균 외에 다른 방법도 있긴 하다. 이 두 값 모두 0~1 사이의 값을 가지며 1..
코사인 vs 유클리디안 유사도, 케이스로 이해하기
벡터 간 유사도 측정에는 여러가지 방법이 있지만, 여기서는 코사인 유사도와 유클리디안 유사도만 다룬다. 기본 개념은 구글링 치면 훌륭한 글들이 많으니, 거기서 참고하면 된다. 여기서는 직접 두 벡터를 가지고 요리조리 굴려보며, '직관적으로' 어떻게 다른지 느껴보고자 한다. 먼저 두 벡터가 완전히 동일한 경우를 보자. a = np.array([[1, 0, 0]]) b = np.array([[1, 0, 0]]) print(cosine_similarity(a, b)) print(euclidean_similarity(a, b)) # output [[1.]] [[1.]] 두 유사도 값 모두 1이 나온다. 그 값만 조금 다른 경우를 보자. a = np.array([[1, 0, 0]]) b = np.array([[2..
 하나씩 점을 찍어 나가며
하나씩 점을 찍어 나가며





